
Word embedding is a technique that treats words as vectors whose relative similarities correlate with semantic similarity. This technique is one of the most successful applications of unsupervised learning. Natural language processing (NLP) systems traditionally encode words as strings, which are arbitrary and provide no useful information to the system regarding the relationships that may exist between different words. Word embedding is an alternative technique in NLP whereby words or phrases from the vocabulary are mapped to vectors of real numbers in a low-dimensional space relative to the vocabulary size, and the similarities between the vectors correlate with the words’ semantic similarity.Continue Reading

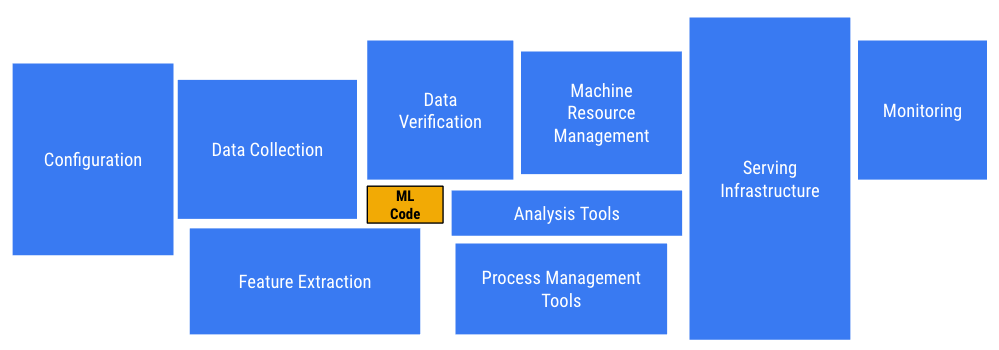
A review of the timing of the most publicized AI advances suggests that perhaps many major AI breakthroughs have actually been constrained by the availability of high-quality training data sets, and not by algorithmic advances.
The preference of high-quality training data sets over purely algorithmic advances might allow an order-of-magnitude speedup in AI breakthroughs.
However, getting this data is neither an easy nor a cheap task, Mechanical Turk tagging data-sets campaigns could cost hundreds of dollars easily and yet with an uncertain quality.
Therefore, the question is how to exploit the minimal data we have and still be able to learn well.
2 Aug 2016